語彙について
2016年11月18日公開
2016年11月18日最終更新
1. 語彙の設計思想
「語彙」は、一般には「語」(言葉、単語)の集合を意味しますが、共通語彙基盤における「語彙」とは、単にそのような語を集めたものではなく、ファイルやインターネットなどを介して行われるコンピューター間のデータ通信を円滑かつ確実に行うことを目的として、概念の代表的な表記としての一つの語の意味や構造、そのような語によって表される概念と他の概念の関係などを明確にした概念の集合を指して用います。共通語彙基盤では、特に混同がない場合は、そのような語で表される概念を「用語」と呼んでいるので、「語彙」は「用語」の集合ということになります。
共通語彙基盤では、類似の用語、重複する用語、分野で意味が異なる同一語といった用語など、コンピューター処理を難しくさせている用語の問題を解決するため、概念的な同一性を保証する形で「用語」を定義しています。
1.1 語彙の階層構造
共通語彙基盤は、次の2つの語彙で構成されます。
- コア語彙
- 分野を超えて使われる共通性のある用語(【人】【氏名】など)の集合
- ドメイン語彙
- コア語彙の概念を継承して定義した、分野固有の用語の集合
このように、共通語彙基盤で定義される語彙は、最も基本的な語彙を対象とするコア語彙をベースとし、それを継承した個別の分野毎のドメイン語彙が作られて行くという階層構造をもっています。
1.2 語彙の利用モデル
語彙(コア語彙、ドメイン語彙)の定義は、XMLのスキーマおよびRDFのスキーマとして提供されます。それで、実際のデータ交換に用いる、語彙に基づいたデータ項目とその構造は、それらの語彙スキーマを参照してXMLとRDFそれぞれに定義することができます。
そのようなデータ構造定義に加え、各項目の値の範囲、書式、使用可能な文字セットの指定などの情報(データモデル)は、それら各定義ファイルへの参照を含め、Data Model Description(DMD)でまとめて記述します。そして、語彙を用いたデータの利用者間でDMDを共有することによって、語彙に基づくデータ交換が実現されます。
DMDについての詳細はDMD(Data Model Description:データモデル記述パッケージ)についてで説明します。
1.3 コード・IDの設計思想
一般に、データの値として、自然言語による説明文ではなく符号によって対象を表すことがありますが、共通語彙基盤でもデータ項目の値としてそのような符号を用いることができます。共通語彙基盤で用いる符号としては「コード」と「ID」の2種類があります。
「コード」は、対象がもつ特定の属性を、機械処理しやすい形で、漏れなく表現できるようにした符号です。例として、国コード、都道府県コードなどが挙げられます。「ID」は、所与の適用範囲の中で、対象を他のものと区別して特定するための符号です。例として、社員番号、利用者IDなどが挙げられます。
コードとIDの詳細はIMI共通語彙のIDとコードについてで説明します。
2. 語彙の仕様書
IMI共通語彙基盤の背景で説明しているように、概念にはクラス概念とプロパティ概念がありますが、共通語彙基盤では概念を「用語」と呼んでいるので、それらをクラス用語とプロパティ用語といい換えることができます。そのため、これ以降、「クラス用語」「プロパティ用語」として説明します。
プロパティ用語は、クラス用語の性質・属性を表すものとして、クラス用語を何らかの値や、他のクラス用語と結び付けるために用いられます。たとえば、【期間】というクラス用語は、【開始日時】、【終了日時】、【説明】というプロパティ用語を組み合わせることができます。このような用語の集合が「語彙」です。
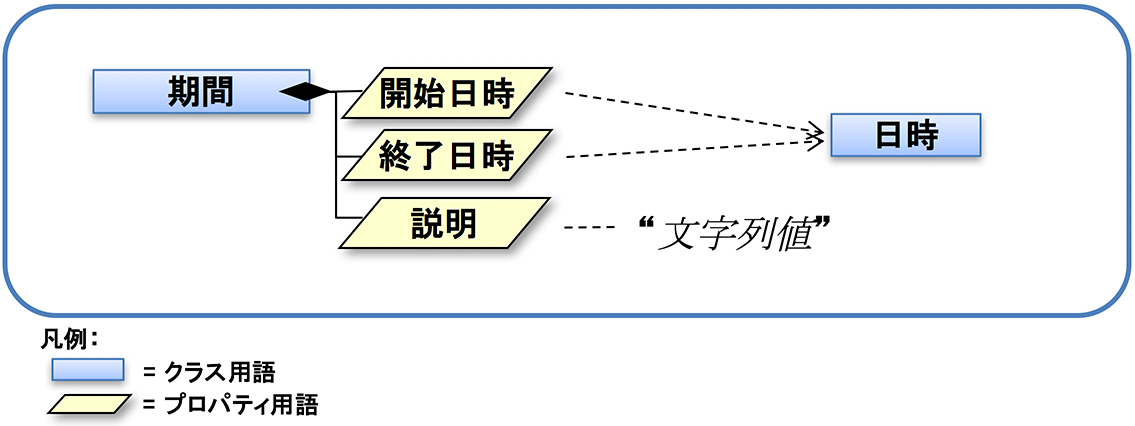
用語には、それ自体の意味と共に、クラス用語とプロパティ用語の関係のような構造があります。また、テキストデータの値の書式制限(文字数の上限など)もあります。従って、用語の集合である「語彙」も、用語に関わるそれら様々な情報を伴ったデータの集合として捉えられます。
2.1 語彙の構造
実際に語彙を作り上げるためには、クラス用語とプロパティ用語およびそれらの関連性を定義する必要があります。それで、クラス用語とプロパティ用語の関係、またそれぞれの用語の表記について以下に説明します。
2.1.1 クラス用語とプロパティ用語
ここまでに説明したように、クラス用語は、何らかの事柄に関する概念を表す用語であり、プロパティ用語は、それらの事柄の性質や事柄と事柄の関係を指し示す概念を表すための用語です。つまり、クラス用語は一つ以上の組合せ可能なプロパティ用語をもち、プロパティ用語は、データ値を直接もつこともあれば、他のクラス用語と関連付けられることもあります。
クラス用語は、その性質・属性を表すプロパティ用語の組合せで定義されます。そして、プロパティ用語は次のいくつかの情報によって定義されます。
- プロパティ用語の値型
- プロパティ用語によって結び付けられるテキストデータの書式や他のクラス用語をプロパティ用語の「値型」と呼びます。
- 値型がテキストデータの書式の場合、W3Cの「XML Schema Part 2: Datatypes」で定義されたデータ型(xsd:string(文字列)、xsd:date(日付)など)、あるいは他の標準化されたデータ型を指定します。この場合は、プロパティ用語が値を直接もつ形になります。
- 値型がクラス用語の場合は、値型として指定されたクラス用語がもつプロパティ用語の値型へと間接的に結び付けられます。つまり、そのような用語を実装(表現)したデータは、いくつかのクラス用語を経て末端のテキストデータにたどり着くような階層構造をもちます。
- プロパティ用語の回数
- プロパティ用語は、クラス用語を何らかの事柄に結び付けるために用いられるものですが、同一のプロパティ用語で同時に別個の事柄と結び付けることもあります。そのような場合は、同一プロパティ用語を複数回使用することになります。このように、一つのクラス用語に対して、プロパティ用語を何回使用できるかを最小出現回数と最大出現回数で定義したものをプロパティ用語の「回数」と呼びます。
- 例えば、クラス用語【定期スケジュール】に対して、プロパティ用語【開催期日】を2回使用して、“火曜日”“木曜日”という2つの曜日が結び付けられる場合があります。
2.1.2 用語の表記
共通語彙基盤では、クラス用語、プロパティ用語の表記として、制約事項および推奨事項があります。制約事項は必須の規定です。推奨事項は必須ではありませんが、語彙を円滑に行うには可能な限り従うことをお奨めするものです。
- 制約事項:
- 用語は、XML1.0第4版に準拠した要素名として記述できるようするため、例えば、用語に半角カタカナを用いたり、先頭に数字を置くことはできない。また、使える漢字等の範囲に、XML構文規則から来る制約がある。
- なお、文字の符号化は、ISO/IEC 10646に従うものとし、エンコーディングについては、UTF-8、UTF-16、UTF-32などを必要に応じて選択することになる。異なるエンコーディングの間での相互変換については実装時に留意する必要がある。
- 推奨事項:
- コア語彙とドメイン語彙は名前空間が異なるので区別は付くものの、それらの間での語彙の名称は、可能な限り重複を避けること。
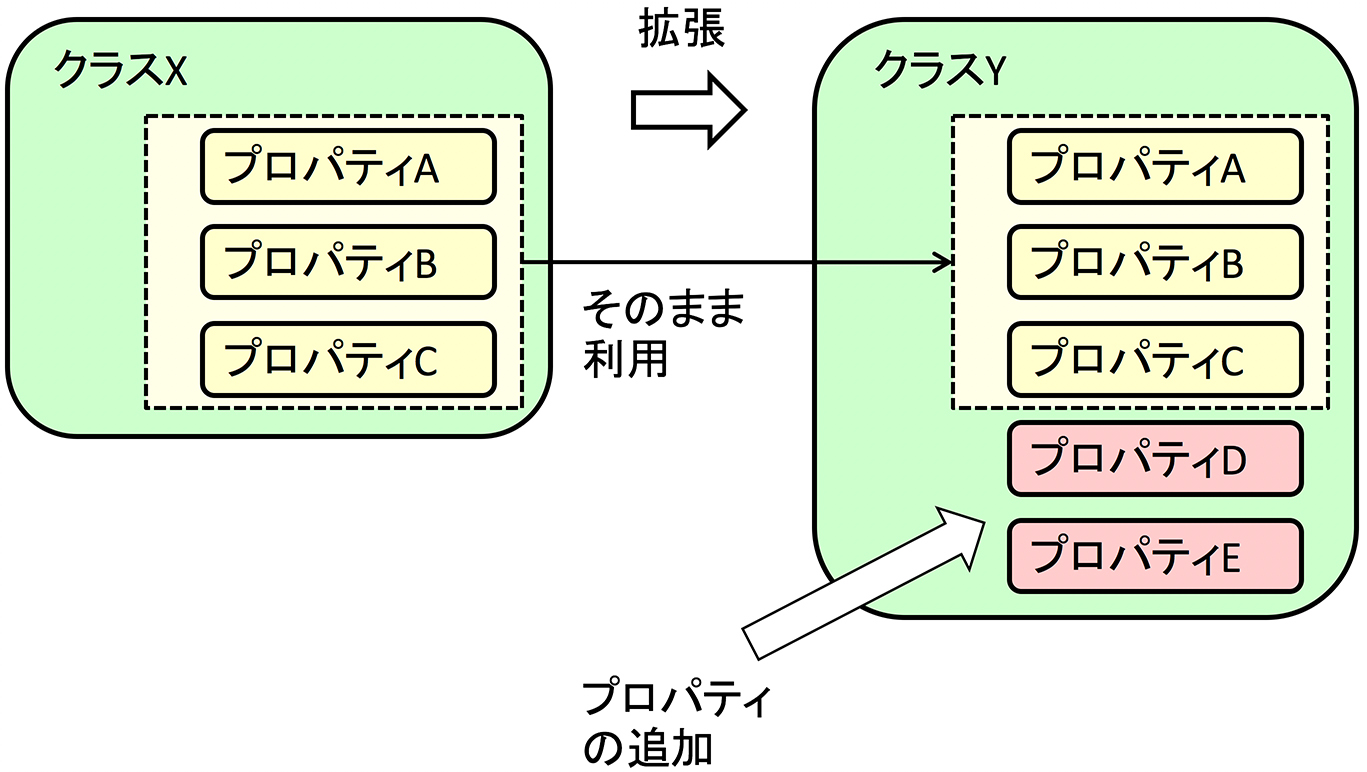
2.2 継承による新規クラス用語の作成
語彙のクラス用語をベースに、プロパティ用語の追加、回数の変更などを行って新たなクラス用語を定義することをクラス用語の「継承」と呼びます。
継承には「拡張」と「制限」の2種類がありますが、共通語彙基盤の核となる「コア語彙」では、プロパティ用語を追加してクラス用語を派生させていく「拡張」の手法を使っています。
このような継承の考え方を用い、「コア語彙」を継承して「ドメイン語彙」や個別の応用で用いるデータモデルに必要なクラス用語とプロパティ用語を新規に作成することができます。
なお、共通語彙基盤で用いる語彙を作成する場合は、必ず次の制約事項に従って用語を作成するようにしてください。
- 制約事項:
- 新規のクラス用語は、コア語彙をベースとした継承によって定義すること(少なくともコア語彙の全ての型のベースとなる基本型としての「ic:事物型」は継承する。なお、直接の継承元がコア語彙のクラス用語ではなくても、継承関係を辿った中にコア語彙のクラス用語(例えばic:事物型)が現れればよい)
継承の考え方に基づいて新たなクラス用語を定義して語彙を設計する場合は「拡張」を用います。「制限」は、実際のデータを記述するための応用語彙において必要に応じて行われ、コア語彙やドメイン語彙など既存の語彙に対し、使用するプロパティ用語の選択、回数変更、などの制約を加えます。具体的な制限の内容は、XMLスキーマ、RDFデータモデル記述で表現され、それらをDMDで指定します。
3. 語彙の実装
2. 語彙の仕様書 では、語彙の概念やデータモデルを抽象的に説明しました。ここでは、語彙をコンピューターを使った実際のデータ交換に用いることができるよう、RDF、XML、IMI構造化項目名、の3つのデータ形式で実装(表現)する方式について説明します。
3.1 RDF形式
オープンデータとしての情報公開の基盤となるデータ記述言語であるRDF(Resource Description Framework)によって、語彙を用いたデータを表現することができます。
3.1.1 RDFデータモデルへの変換ルール
語彙をRDF形式で表現するには、RDFスキーマ、及び必要に応じてOWL(Web Ontology Language)を使った定義を行います。そこで、語彙のモデルと、それを表現するために用いるRDFスキーマ・OWLの記述の対応関係を次に記します。
| 【語彙のモデル】 | 【RDFスキーマ・OWLの記述】 |
|---|---|
| クラス用語 ⇒ | owl:Class若しくはrdfs:Class |
| プロパティ用語 ⇒ | owl:ObjectProperty、owl:DatatypeProperty若しくはrdf:Property |
| 値型 ⇒ | rdfs:range |
| 継承 ⇒ | rdfs:subClassOf及びrdfs:subPropertyOf |
| 定義域 ⇒ | プロパティ用語の定義において、schema:domainIncludesでヒントを与えます。厳密な定義域をrdfs:domainで示すと、拡張などの際に矛盾を生じるおそれがあるので注意してください。クラス用語定義でowl:Restrictionを用いたプロパティ制約を記述することもできます。 |
この対応関係を使って語彙モデルをRDFスキーマに変換した例と、それに基づくRDF表記の例を次に記します。

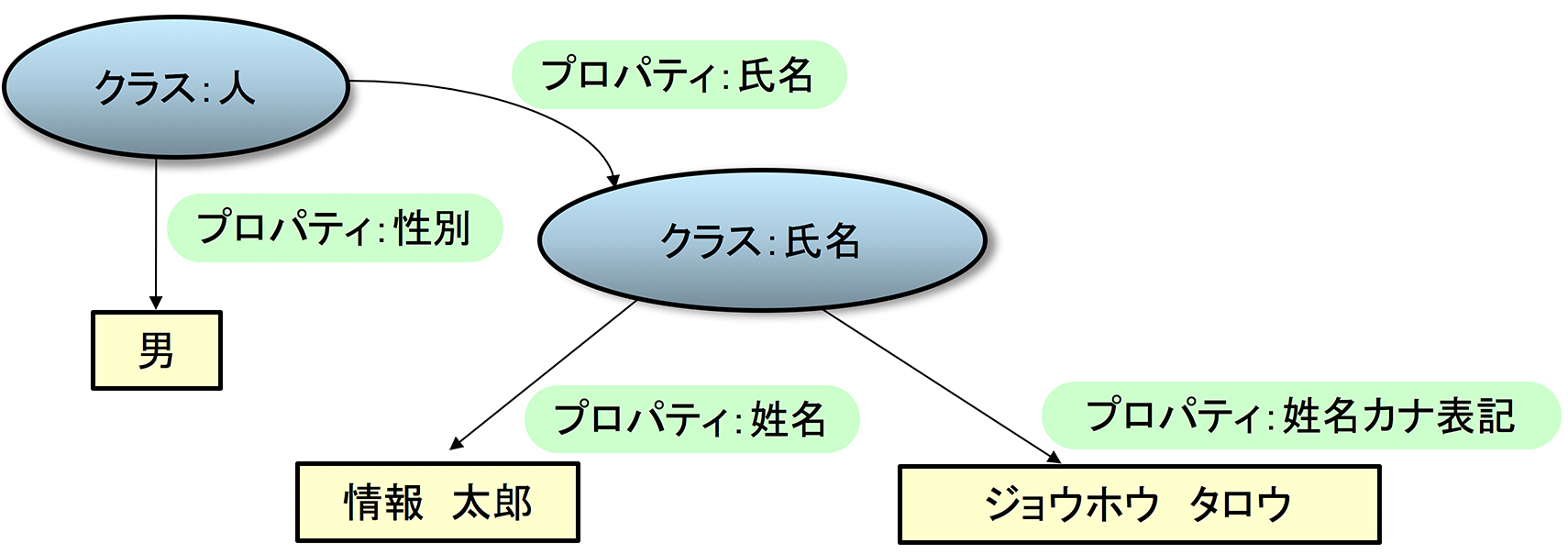
@prefix ic: <http: //imi.go.jp/ns/core/rdf#> .
<#Person1> a ic:人型 ;
ic:氏名 [
ic:姓名 "情報 太郎";
ic:姓名カナ表記 "ジョウホウ タロウ";
].
3.1.2 RDFによる個別データモデルの記述
個別の応用における具体的な用法は、コア語彙/ドメイン語彙に対し、クラス用語と組み合わせて実際に使用するプロパティ用語の選択、回数指定、プロパティ用語に結び付けられたテキストデータの値の制限などの制約を加えることによって示します。このような制約記述は、RDFの場合、Shapes Constraint Language (SHACL) (http://www.w3.org/TR/2016/WD-shacl-20160530/)によって表現します。これらの記述についての詳細は、別資料の『DMD仕様書』を参照してください。
3.2 XML形式
W3Cの標準仕様XML(Extensible Markup Language)で語彙を用いたデータを表現することもできます。これは主にコンピューター間でのデータ交換で用いられます。
以下に語彙構造をXMLのスキーマ定義言語であるW3C XML Schemaにマッピングする方式について説明します。
3.2.1 W3C XML Schemaへの変換ルール
語彙のモデルと、それを表現するためのXML Schemaの記述の対応関係を次に記します。
| 【語彙のモデル】 | 【XML Schemaの記述】 |
|---|---|
| クラス用語 ⇒ | xsd:complexType要素 |
| プロパティ用語 ⇒ | xsd:element要素 |
| 値型 ⇒ | xsd:elementのtype属性 |
| 継承 ⇒ | xsd:extension要素 |
| クラス用語が使うプロパティ用語 ⇒ | クラス用語を定義するxsd:complexType要素内のxsd:sequence要素の下に列挙されるxsd:element要素によって、そのクラス用語が使うプロパティ用語を記述 |
この対応関係を使って語彙モデルをXML Schemaに変換した例と、それに基づくXML表記の例を次に記します。

<ic:人>
<ic:氏名>
<ic:姓名>情報 太郎</ic:姓名>
<ic:姓名カナ表記>ジョウホウ タロウ</ic:姓名カナ表記>
</ic:氏名>
</ic:人>
3.2.2 XMLによる個別データモデルの記述
個別の応用におけるデータモデルは、コア語彙/ドメイン語彙のクラス用語に対し、実際に使用するプロパティ用語の選択、回数指定、プロパティ用語に結び付けられたテキストデータの値の制限(文字数の上限など)などの制約を加えることによって構築されます。このような制限は、XMLの場合、一旦IMI語彙のクラス用語を再定義し (下記ノート参照) 、それに基づいて具体的なデータモデルを定義したXMLスキーマ(データスキーマ)を作成することによって表現します。これらXMLスキーマファイルについての詳細は、別資料の『DMD仕様書』を参照してください。
クラス用語の“再定義”とは、W3C XML Schemaのxsd:redefine機能を使い、所属する名前空間を変えることなく、クラス用語(XMLスキーマの型)で用いられるプロパティ用語(XMLの要素)の出現回数を変えたり(特定のプロパティ用語を使用しないことも含む)、データの値(XMLの文字列)の記法を定めたりすることを指します。
3.3 IMI構造化項目名
「IMI構造化項目名」は、階層構造をもつデータの位置を文字列によって表現するための仕様です。
IMI構造化項目名の記法を利用することで、階層構造をもつデータを表形式のデータとして表現することができるようになるため、階層構造をもつデータの表計算ソフトウェアによる編集や、表計算ソフトウェアなどで作成されたデータから階層化されたデータへの効率的な変換ができるようになります。
3.3.1 IMI構造化項目名への変換ルール
IMI構造化項目名は、前述のRDFやXMLを用いた表記とは異なり、予め特定の項目群の構造を定めたスキーマは用いず、そのまま文字列として表現します。IMI構造化項目名の基本構造は一つのクラス用語と 任意の数のプロパティ用語を「>」(半角)又は「>」(全角)で区切って並べた以下のようなものです。
クラス用語>プロパティ用語>プロパティ用語>・・・
この記法に則って記述しデータ項目名の例を以下に示します。
人>氏名>姓名
人>氏名>姓名カナ表記